Developers have unique storage needs as a result of the work we do. I've got a subversion server that needs storage, directories full of libraries, IDE stacks, and a metric crap-ton of virtual machines and their install ISOs.
When I first started this project, I decided that I needed reliable, scalable, centrally located and accessible disk space. It also had to be
fast! Finally, it had to be tidy and easy to administer. I might as well have asked for a pony while I was at it.
Having an old audio rack, a 1000' spool of cat 5E, and some power tools at my disposal, I decided that everything would go right in to a rack-mounted box where I could maintain the wiring easily. Lighting would come in handy, too, for those times when I have to crawl behind the rack and hook up a monitor or keyboard.
After some trial and error, I found a very fast, versatile, fault resistant, and scalable setup that uses mostly commodity hardware (
for those hardware failures that only happen at 8PM on a Saturday night) and open source software. The rack utilizes three servers, running three operating systems tuned for the servers primary purpose.
All of the boxes and virtual machines can be controlled from my jail broken iPod Touch or my Blackberry Storm. A bonus to this approach is that I can use the iPod to control my iTunes from anywhere in my apartment. The Linux and BSD boxes can be administered via SSH with a private key authentication, and the Windows boxes can be administered using RDP with Samba authentication. Samba provides the user names and accounts for both the Windows and Linux boxes as a single point of administration for users/passwords.
Here is the basic setup...
Boxes
The storage server, named 'storage', is a 4U chassis with an external hot swappable 5 drive bay. It sports an Asus A8N32-SLI Deluxe which rocks an AMD Opteron 146, 4 gigabit NICs, 1 100mbit NIC, a GeForce 8500 GT, and two gigs of RAM (had 3 gigs, but burnt out a dual channel kit.... dropping in 4 gig sticks on next upgrade cycle) which acts as a dedicated disk buffer/cache. Storage is running Fedora-10-x86_64 Linux and exports disk space over iSCSI on two subnets.
The router, named 'drawbridge', is an old EMachines EMonster 600 with three NICs, an old Quantum BigFoot 5.25" drive, and about half a gig of RAM. It runs a BSD derived OS, pfsense which is actually a m0n0wall fork. The services provided for the network are DNS, DHCP, DHCP forwarding to DNS, UPNP, NAT, traffic virus scanning, traffic graphs, and a 3-way firewall.
Unfortunately, this box is getting long in the tooth. When I upgrade my server, that box will replace the router. The rule of thumb for network traffic is 1 MHz per mbit per second; 600 MHz just doesn't cut it
for running several gigabit trunks.
Slacker, the primary server, is an AMD 900 MHz Duron with half a gig of RAM, and 5 NICs. It runs a customized and slimmed down version of Slackware-10.2 Linux (ergo, the name slacker!). Slacker provides domain authentication and storage via Samba, as well as being a Subversi
on server. The storage for the services running on Slacker is on the storage server and imported via multiple, redundant, striped iSCSI links.
Network Design
The primary server gets its storage from the storage server over a dedicated switch using two connections from each box for redundancy. This subnet is 192.168.10.0/28 and is isolated from the rest of the network. There is also a dedicated switch and subnet (192.168.5.0/28) for storage accessed by the desktops. For performance, neither of those subnets go through the router.
Publicly addressable servers are on a 192.168.0.0/24 subnet and are only accessible through the router (all traffic has to pass through the routers firewall). The wireless access point shares the switch and subnet of the rest of the LAN on 192.168.1.0/24.
Any traffic headed from the LAN to anywhere else has to pass through the firewall on the gateway. Internet traffic comes from a cable modem and hits a patch panel which is directed to the routers WAN NIC.
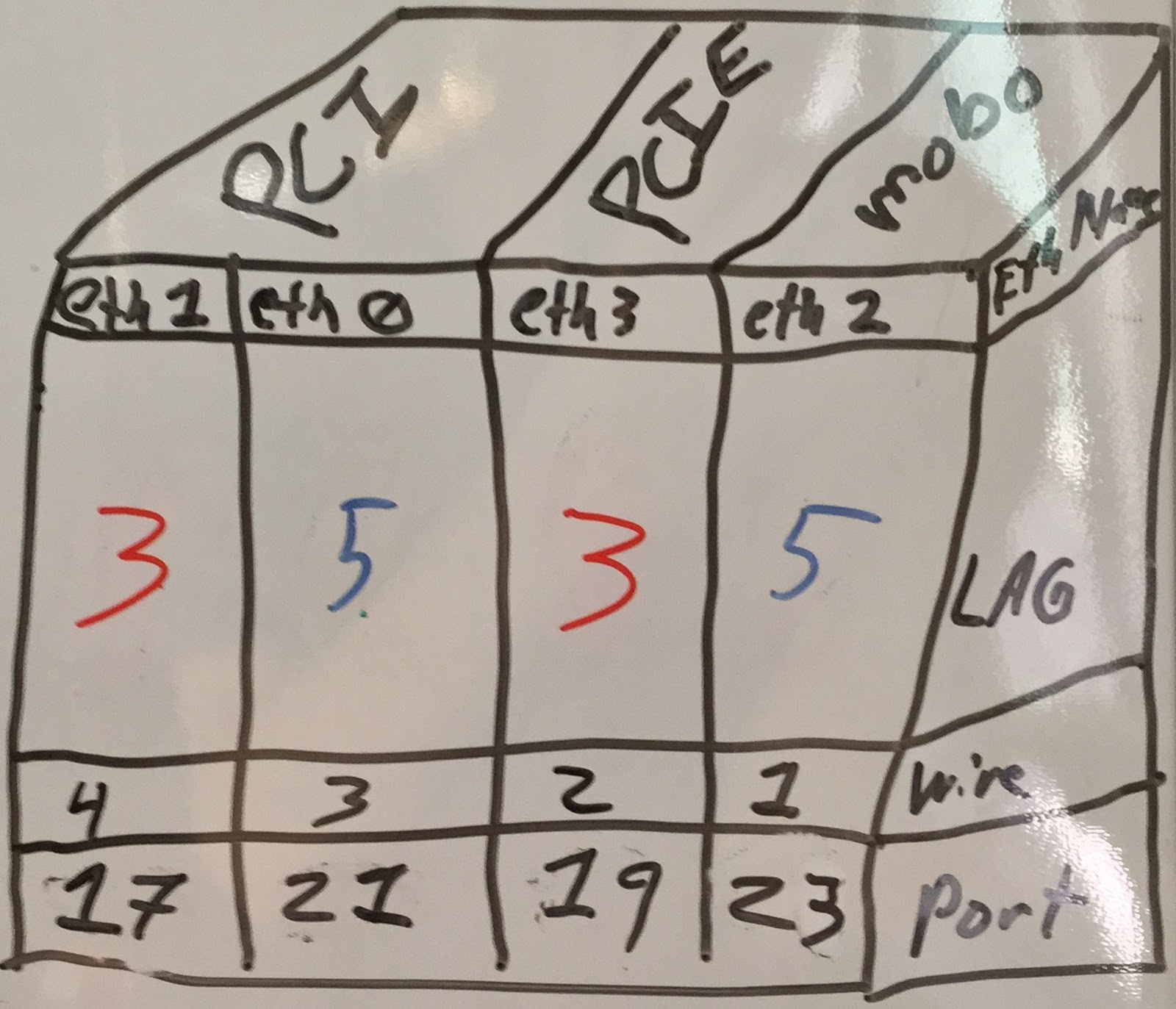
Each box has two links to the backbone switch so that one NIC on each box can fail without causing a problem. Multipathd is utilized for round robin striping over the iSCSI connections on the backbone. Every few MB the active connection to the storage server is changed. A non-functioning link is dropped from the rotation schedule until it is functional again. Since I'm not using a managed switch with LACP, Linux policy routing is used so that a box responds on the interface that got the incoming packet; for fail-over purposes, ARP proxying is allowed on the backbone NICs for both boxes. It confuses the switch to no end, but the important thing is that it works.
Storage
Each of the drives are partitioned in to 5 100GB slices set for Linux software RAID which allows for automatically adding to RAID groups on the fly. From here 5 RAID-10 devices are created with a 128K chunk size:
[root@storage sbin]# cat /proc/mdstat
Personalities : [raid10]
md3 : active raid10 sde3[0] sdd3[3] sdc3[2] sdb3[1]
195318016 blocks 128K chunks 2 near-copies [4/4] [UUUU]
md5 : active raid10 sde5[0] sdd5[3] sdc5[2] sdb5[1]
195318016 blocks 128K chunks 2 near-copies [4/4] [UUUU]
md6 : active raid10 sde6[0] sdd6[3] sdc6[2] sdb6[1]
195494656 blocks 128K chunks 2 near-copies [4/4] [UUUU]
md1 : active raid10 sde1[0] sdd1[3] sdc1[2] sdb1[1]
195318016 blocks 128K chunks 2 near-copies [4/4] [UUUU]
md2 : active raid10 sde2[0] sdd2[3] sdc2[2] sdb2[1]
195318016 blocks 128K chunks 2 near-copies [4/4] [UUUU]
Four of these devices are then exported over iSCSI. The fifth has an XFS file system laid on top of it which holds a bunch of .img files that are exported over iSCSI. Using pre-allocated files boosts virtual machine performance since the Linux kernel will allocate RAM as a buffer to the file, as well as allowing VirtualBox to import it as a disk directly over iSCSI. As a bonus, the files compress really well (all unused space is filled with zeros) and allow you to carry a single compressed file that has an OS on it.
Performance
Performance is generally decent:
[root@storage sbin]# hdparm -tT /dev/md2
/dev/md2:
Timing cached reads: 1604 MB in 2.00 seconds = 801.86 MB/sec
Timing buffered disk reads: 414 MB in 3.01 seconds = 137.69 MB/sec
The thing to remember is that you can have low latency with low throughput, or high latency with high throughput, per link. For IO bound operations, you'll want the throughput, for CPU bound operations, you'll want low latency. The trick is finding a good middle ground. The other trick is cheating as much as possible to lower the latency.
As with almost all computer related topics, you can trade off space for time. In almost every instance this is a good trade off; time is the only resource you can never get back. Instead of reading and writing directly to disk, throw a metric crap-tonne of hardware at the problem in the form of RAM. It is dirt cheap these days, and performs an order of magnitude faster than a hard drive. Using RAM as a read/write buffer allows for storing read-ahead from the drive, as well as higher cache hits from the page cache. I dedicate all RAM on the storage box as buffer and make sure that the OS is doing all of the heavy lifting for writing out dirty pages to disk; the read cache buffer will shrink as needed to allow more pending writes. Here are the (somewhat aggressive) virtual memory setting for the storage box:
/proc/sys/vm/dirty_background_ratio 1
/proc/sys/vm/dirty_expire_centisecs 1499
/proc/sys/vm/dirty_ratio 90
/proc/sys/vm/dirty_writeback_centisecs 248
/proc/sys/vm/swappiness 95
/proc/sys/vm/vfs_cache_pressure 100
For more info about these Linux kernel settings, see The Linux Page Cache and pdflush:
Theory of Operation and Tuning for Write-Heavy Loads. Basically the settings above can be interpreted as, “Swap as much out as possible, write soon and often, make the OS do (almost) all of the writing on behalf of user processes, and use as much RAM (and then some) as needed to accomplish this.”
Having a large RAM buffer between the disks and the clients increases throughput while keeping latency low due to a high cache hit ratio. Read-aheads from disk are kept in RAM before they are requested. A further tweak (depending on workload) is using the anticipatory IO scheduler instead of the CFQ. This values throughput over latency when requesting IO to or from the disks.
The network stack has also been tweaked a bit. Choices of congestion control are reno or cubic. Proxy ARP, dsacks, sacks, and low_latency are utilized while tcp_reordering, tcp_max_syn_backlog, and tcp_mem are cranked all the way up.
Backups
Using a flat file eases offsite backups; sync your disks (use an LVM snapshot, if possible!), copy the flat img file to a temp directory, crunch it at full compression, and split it into 345 Mb chunks. 345 Mb allows for writing either two chunks to a CD, 13 chunks to a single layer DVD, or 24 chunks to a dual layer DVD. Note Mb = 1 million bytes and you need a bit of head room on disc for the file system and such accounting metadata. At any rate, fire up your coaster-maker with a quality dual layer DVD+R and burn off your backups. I use a deposit box at my bank for backups; it's well worth a yearly fee of $75 to have a secure off site repository for your data... unless your data isn't worth anything. For the rest of us, follow SOP, at the very least two medias (I'd go so far as to say 3 is probably optimal-magnetic,optical and flash), two locations, encrypted, at most two keys (or a safe combination split up over 3 or 5 people), and make sure to test the restore procedure.
While having a good backup to restore from makes me feel all warm and fuzzy, I'd prefer to avoid the situation all together, which is more difficult than it sounds. A rack mounted storage box is a somewhat hostile environment for computer components. On bootup, unless you've got drives that'll do a staggered spin up, you strain your power supply as it has to get a bunch of metal platters up to 7200 or more RPMs within a second or two. Once up to speed, the drives rattle around in their cramped, hot, bay. During transfers, the most sluggish drive is going to be under constant strain to keep up with the rest of the drives. As the contents of the drive are moved across the chipset to RAM and various busses, TCP/IP stacks are checksummed, data is stripped out of TCP/IP stacks, and operating system services buzz around flushing buffer caches and building page caches, the box is going to get downright hot! Marginal components aren't going to make it too long under these conditions. This is where using quality parts and having spares on hand is going to make your life easier. In the last two years, I've lost two cheap RAM sticks, two harddrives, and two power supplies.
To help combat hardware failures, I've installed two ball bearing fans that draw the hot air from the top of the box and push it down in to the exhaust stream to get it out of the box and away from the power supply. The air filter on the front intake is coated in a aerosol lithium oil to catch more of the dust that would have otherwise gotten through and clogged the fans. All of the SATA cables are run around the perimeter of the box inside a mesh sleeve to allow for better air flow through the box. All of the fans wires are in sleeves also. To cut down on CPU usage and increase redundancy, the drives were switched from a RAID 5 configuration to a RAID 10 configuration. The tradeoff was 33% less space, but more throughput with less latency.
(More in my next blog...)