Right now I'm sitting around, surrounded by tools and parts, waiting for drives to finish zeroing out so I can make a second ZFS pool. I'll get back to that in a minute. First I should break down how I currently have my server setup.
My VM server is being rebuilt at the moment, so I've offloaded running virtual machines to my desktops; they're beefy enough to handle the job for the moment. That leaves my core switch, router and storage server in the rack. You can skip the break down for the tl;dr section after the list.
- Switch
- TPLink TLSG2424 - it's what you'd expect from a ~$200 switch that has higher end abilities, it's kind of junky and doesn't support the higher end features great, but it mostly works most of the time. Has VLANs, LAGG, SSH, QOS, SNMP, etc. A couple features are buggy and the documentation is terrible, but once again, what did you expect for ~$200?
- Connects to the core switch to the core router and servers via patch panel.
- Router
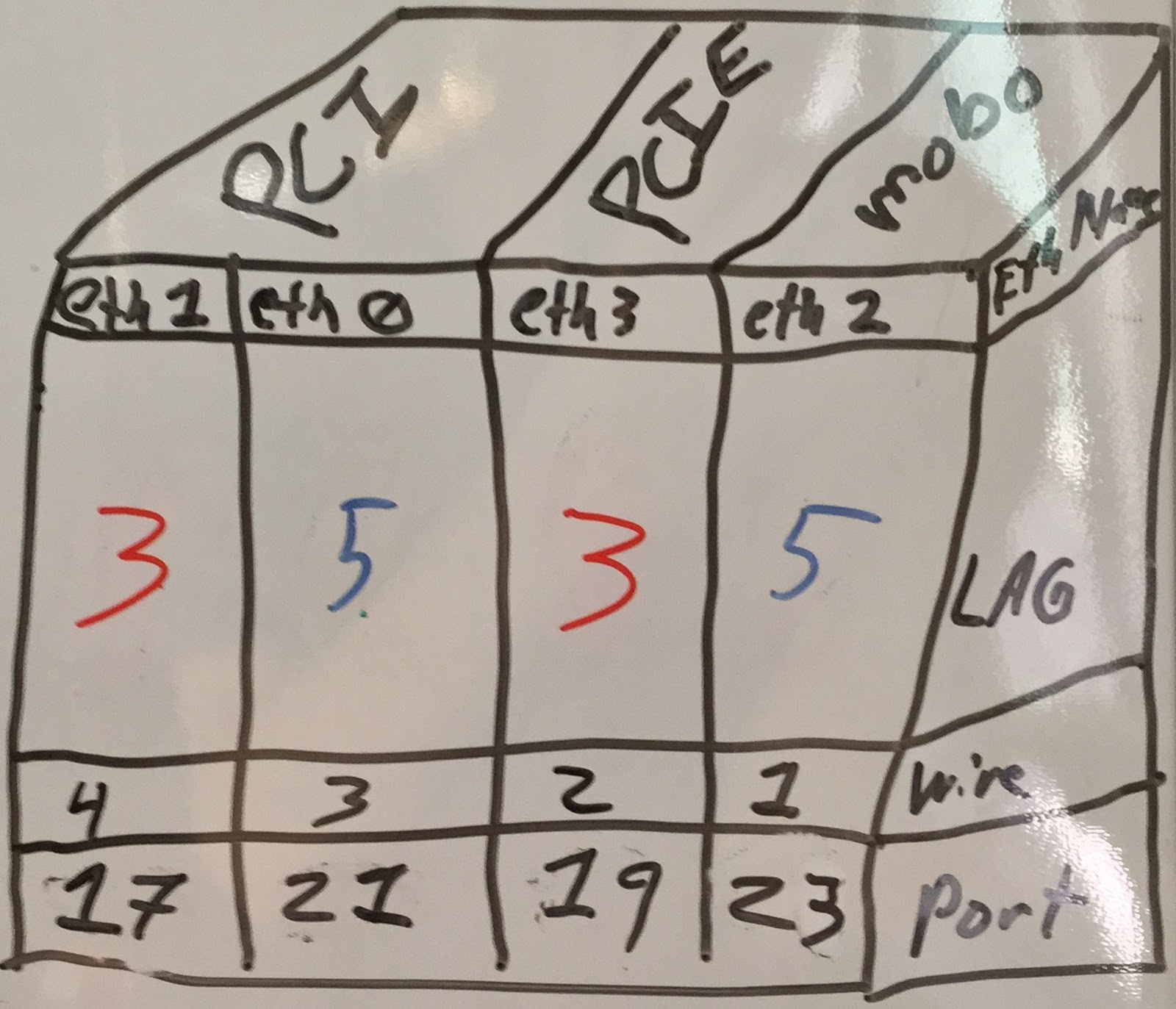
- PFSense box (dual core Celeron w/ 2 GB RAM) with 7 NICs, 6 of which have drivers for BSD, 5 of which work flawlessly. One interface on the PCIE bus is a backup-backup wireless AP, the driver tends to wedge from time to time and the AP goes MIA. Not a huge deal, but I wish it worked without issue. The on board NIC doesn't work at all which isn't a huge deal, but it forces me to run the WAN link over the PCI bus.
- The NICs are spread over the buses (PCI and PCIE) such that one NIC on each bus makes up a bond - 1 PCI and 1 PCIE NIC to spread the traffic and interrupts. The WAN is on the PCI bus (lower bandwidth requirements - but I'll get to bus flooding later), and the WLAN is on the PCIE bus. 1 bonded pair goes to the LAN subnet/VLAN and another bonded pair go to the storage network/VLAN.
- Uses LACP to switch for bonding
- Storage Server
- Slackware Linux box (AMD 6 core, 32 GB RAM) with hand compiled kernel + ZFS on Linux patches with 4 NICs and 10 disks.
- NICs form 2 bonded interfaces from a PCI/PCIE NIC pair each to spread the bus load and are bonded to the "storageGateway" subnet on the router, via the switch, using adaptive load balancing (ALB) on one bond and LACP on the other.
- Disks are spread over the PCIE and SATA buses into 4 ZFS mirrored vdevs; 3 vdevs have 1 internal disk and 1 external hot swappable disk where the internal drives use a PCIE controller and the external drives are wired to the SATA bus and primary onboard disk controller. 1 vdev has both disks in external hot swappable sleds for upgrading the vdev without opening the rig - this mirror uses the second disk controller on the motherboard since the primary onboard controller can only handle 4 SATA channels. 1 disk is the OS drive and the other is an SSD dedicated to read caching and write buffering.
 |
| Switch logical view : Rows are LAG #, VLAN #, Port # (colors are bond association on other pictures) |
 |
| Router logical view |
 |
| Storage Server logical view |
 |
| Big Picture logical view |


Yes, my server closet is literally a closet.
Get To The Point Already!
So, now we've established that I'm the world's worst sysadmin, let's get on to the point of this post, shall we? I've got two issues that I need to solve :
- I want to be able to fully utilize all of the NICs on the storage server and all the links in between.
- I want to move my backed up VM images to a temporary ZFS storage pool so I can break the original into two pools - one with deduplication turned on, one without deduplication turned on.
I've Got Issues, But That's Not The Point
As to the first point, LACP only allows balancing by a source/destination route that traverses a single link. The workaround for this is when I'm using a Linux to Linux connection to have two links on each side use adaptive load balancing and put those ports on the switch in "dumb mode" so they don't try to do anything clever (which they do from time to time). But between the LAN and storage gateway networks is the router, which links to the LAN with a LACP bonded NIC pair. BSD has another LAGG mode called "round robin" which should send and accept packets using both links. This also relies on the switch not being "clever".
Should that work (it's been iffy in my first tests of it), then we've got another issue - the bonded interfaces on the storage server are both on the same subnet. Since by definition a subnet can only have one gateway, I've got a problem; all responses will be sent along one logical link because of this routing policy, even if both NICs in that logical link are being used. What I want is to have the storage server respond on the least busy of the two NICs in the bonded pair.
Which brings me to the second issue I have; I want full bandwidth between my Linux desktop and the storage server because I'm moving large amounts of data to backup the ZFS pool snapshots to a new temporary pool on the desktop. The reason for this being that I used mirrored vdevs to make up the storage pool. Mirrored vdevs trade off space for speed and protection. You lose 1/N of the storage in the vdev (since a mirror can be N-way, not just a pair), but you gain IOPS and raw throughput. This is a topic that could span pages, but I'll just say that smarter people than myself have looked at the problem space and said, as a general rule of thumb, use mirrored vdevs if you don't have a reason not to. More information for the curious is here.
In my case, I have a lot of VMs that I backup as well as full disk images of my laptop. A lot of this data is static, so I can make another trade off; instead of losing half my disk space, I can create a ZFS pool that deduplicates identical blocks so that storing a VM where most of the drive image is unchanged will only take up the storage space of the changes plus a bit of overhead. The new trade off is more complicated. I've got extra IOPS and throughput by virtue of using mirrored vdevs, but I'm losing half my space.
The amount of space that I'd save, as checked by 'zdb', by using deduplication is roughly the amount of disk space I'm losing to the mirror. In this trade off I'm keeping the extra IOPS and throughput while getting back the 50% of disk space I've lost by paying for the deduplication overhead with a metric crap tonne of RAM. Like, tons. Roughly 5 GB of RAM per TB of storage. But the reality is that I also don't get to keep that speed boost entirely. ZFS is a copy on write (COW) file system. COW gives the ability to do many great things at the file system level, but the inherent trade off is that COW file systems fragment. Badly.
When many snapshots are taken, as the data changes it gets placed nearly randomly around the disk surface since blocks that were linear, and still are in the original snapshot, are now spread about. The process of reading a linear disk image, which has the best IOPS/throughput since there is no disk seeking required, goes from the best possible performance (linear) to the worst possible (truly random) quickly as fragmentation increases.
Thus Begins The Point (We Took The Long Way)
Now that these issues have been fully defined, the solutions become obvious. The switch needs to be set to not use LACP, the router needs to use round robin and the server and desktop need to use adaptive load balancing. The gateway issue is handled by turning on ARP filtering on both Linux boxes and employing source based routing (via LARTC - Linux Advanced Routing and Traffic Control). After that, I should export the storage over iSCSI with my ALB bonded interfaces and layer MPIO on top of that.
As for the round robin load balancing between the storage server and the router, there is a caveat to consider. In order for the round robin to work each pair of NICs between the server and the router have to be in their own VLAN so the switch is virtually split into separate broadcast domains. This way there is no confusion when two ports have the same MAC address since the ARP packets aren't crossing VLAN boundaries and poisoning the switch ARP table. This does raise the question as to how much configuration and layering will have to be done to the network stack on the storage server to get the behavior I want from it while having the configuration that allows the trunk between the router, switch and storage server to operate. I haven't tried a setup quite like this, or anything like this, before.
The stuff in the storage pool that is highly redundant should be backed up to a new pool with deduplication turned on, and the stuff that isn't as redundant should be in a pool with deduplication turned off. Splitting the disk in half by partitioning should work (even if ZFS likes to have full disks, it'll work with anything you give it), and the data that fragments the most, the most frequently changed data, should go on the "fast" partitions on the beginning (outside tracks) of the disks. Short stroking the drives this way should also increase IOPS since the drives have effectively half as much surface space to have to seek about when only dealing with one of the storage pools.
Using both pools at once will negate the partitioning performance. The highest average performance would be to partition the disks in half and use one "slow" partition with one "fast" partition per vdev, but data access patterns are very rarely even distributed so this is probably less ideal than figuring out which data is accessed the most, how its reads/writes are distributed and whether its latency sensitive or throughput sensitive. That is to say, there is a lot of tuning potential when I'm ready to recreate the ZFS zpools.
I'm going to break at this point and post when I have some results to show or lessons learned.
I'm going to break at this point and post when I have some results to show or lessons learned.
No comments:
Post a Comment